


Amazon S3 Glacier is a cloud service dedicated to storing archived data that is not likely to be retrieved often. In other words, it is designed for infrequently accessed data. Glacier has a high latency of data retrieval but offers low pricing and high safety for stored archives. In this article, we are going to explain Glacier’s data uploading nuances.
Table of Contents
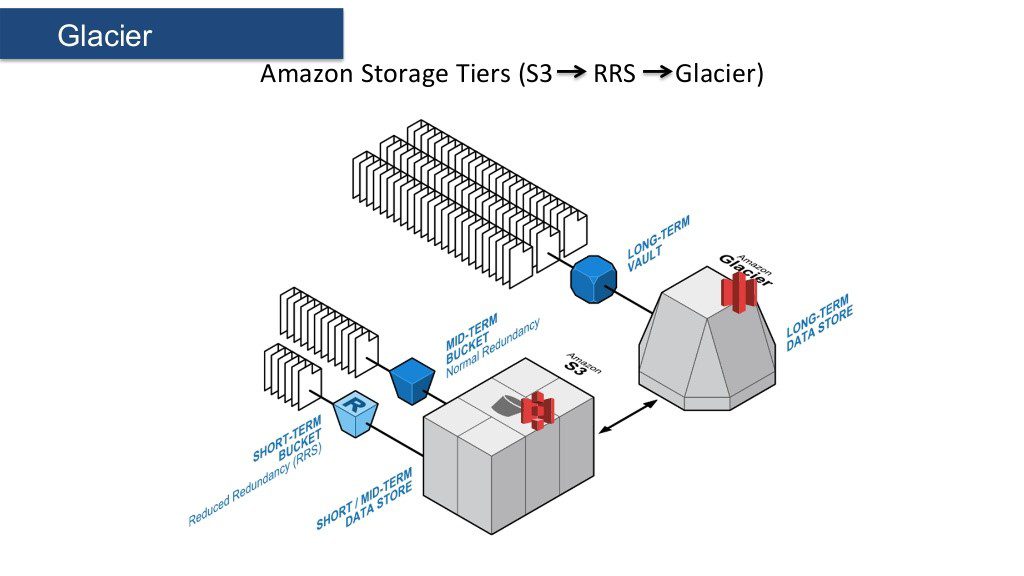
Working with S3 Glacier
Amazon Glacier is a quite cost-effective solution for the prolonged keeping of important data that is not used often. It is a nice choice for a company that possesses a lot of outdated electronic documentation and wants cheap but safe storage. Amazon does not urge its customers to store more or less there, though Glacier's optimal usage model foresees archives to be kept for a longer period of time.
How to use cold storage - like Amazon S3 Glacier - cost-effectively and efficiently? Find out in our whitepaper:

Glacier storage ensures high redundancy, as an archive is stored within multiple facilities at once. The archived data is secured with AES-256 encryption on the server-side. Additional safety is ensured by Vault Lock policies.
The monthly storage price is fixed and varies from $0.004 to $0.013 per 1GB, depending on the region. Retrieval is free for up to 10 GB a month. The deletion of data is free if this data was stored for more than 3 months, otherwise, an early deletion fee would be applied.
Further reading Amazon S3 Glacier Pricing Explained
Amazon S3 Glacier Deep Archive storage class is meant for deep archival data that is only needed very infrequently but can’t be deleted. Storing 1Gb will cost you $0.00099 per month.

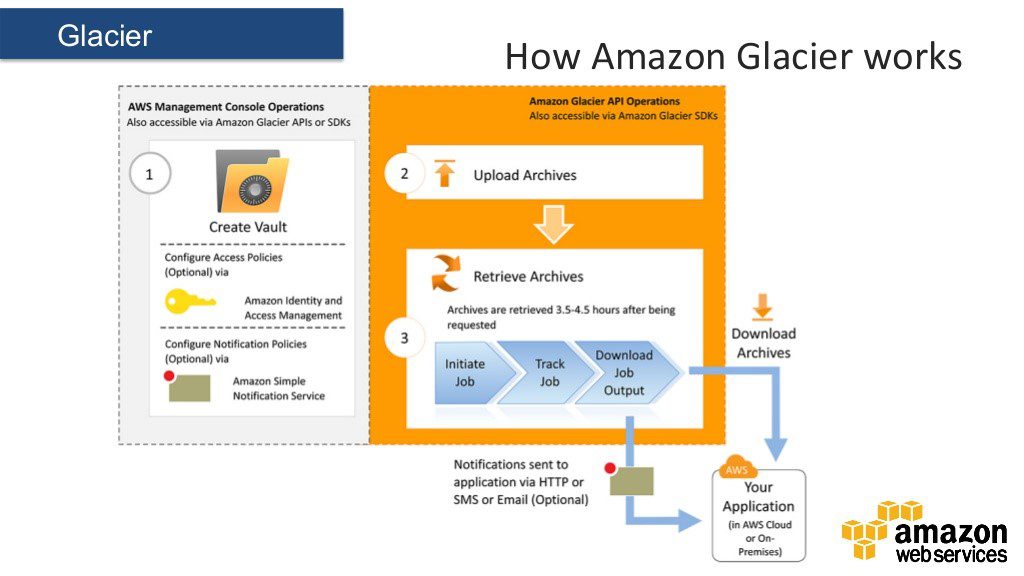
Users have to set up jobs in order to download archives or archive lists in vault snapshots. These jobs run in the background and usually take several hours to complete. There are two ways to upload data
- Direct upload to Glacier from the user's instance.
- Using Amazon S3 lifecycle policies to move data from S3 to Glacier.
Let's explore both of them in detail.
Direct Upload to Glacier
There is no Wizard in the AWS console for uploading archives to Glacier vaults. Users have to do that by creating requests via Glacier REST API or use AWS Software Development Kits (or SDKs) for their own applications. All that requires some coding and AWS provides SDKs with Glacier support for the following programming languages:

- C++.
- Go.
- Java.
- JavaScript in Node.js.
- .NET.
- PHP.
- Python.
- Ruby.
This way of uploading is, therefore, most convenient for users with programming skills or for third-party providers who offer their own tools for S3 Glacier storage management.
Amazon provides two alternative schemes of direct upload to Glacier:
- Upload in a single operation
- Upload in parts
Single operation option is available for up to 4GB of data. Upload in parts is recommended for archives bigger than 100MB: it transfers each part in a parallel session (size of parts is specified by the user). If a session fails, only this part would be missing so a user will have to resend only it alone. No additional fees are charged for multipart upload.
Scheduled Upload to Glacier from S3
Data that is already in AWS’s cloud can be moved to Glacier storage with the help of the lifecycle policy feature. If you do not urgently need some of the files stored in an S3 bucket, it is possible to schedule their transfer to a less costly place - that is what these policies are for.
You can create a policy via your AWS console, in the Properties page of your S3 bucket. Just make sure that the Archive to the S3 Glacier Storage Class checkbox is selected. After a new policy is created, your data will be transferred from S3 to Glacier after the time specified. It will not show up in Glacier storage, however - you still could view it from the S3 bucket. You would have to restore this archive from Glacier before any other operations would be available.
Further reading How to Upload Files to S3 Glacier with Lifecycle Rules
Scheduled upload to Glacier is the best option in case the user's data is already in S3. It is also a more convenient way for companies with a great flow of electronic documentation because it allows an administrator to automate the archiving of a large number of items. On the downside, this additional tier of storage results in extra storage fees plus a request fee for archiving to Glacier.
Summary
Both ways of transferring data to Glacier storage have certain pros and cons. Let us summarize their differences to make the comparison easier.
| Direct Upload to Glacier | Archiving from S3 | |
| Time consumption | Multipart upload allows faster archiving | Scheduled archiving jobs automate the process and save time |
| Fees that apply | Glacier storage fee |
|
| Preconditions | An interface must be set up programmatically in order to send uploading requests to AWS | Data must be stored in S3 in order to be transferred to Glacier |
| Visibility | Archives are visible on the Glacier control panel | Archives are not visible on the Glacier side and must be managed via the S3 control panel |
MSP360 Backup supports Amazon Glacier and you can perform direct uploads of the data to your Glacier storage. It's also possible to create and manage lifecycle policies and transfer archives to Glacier directly from the MSP360 Backup user interface.
- Amazon S3 storage classes and their use cases
- Pricing principles of Amazon S3
- Monthly cost estimates for Amazon S3 cloud storage and MSP360 Managed Backup – and more
