




You recently learned about RTO – one of the key points of any backup and disaster recovery strategy. In this article, you will learn about the Recovery Point Objective (RPO), which stands for data loss in cases of disaster, and how it influences backup and recovery strategies.
What Is RPO in Disaster Recovery?
The Recovery Point Objective definition encompasses the volume of data lost in cases of service downtime. If you have already recovered a failed service within a few minutes, it does not necessarily mean that your company will only lose a few minutes of work. The data recovered could have been captured a week ago, so the real data loss would be one week’s worth, in that case – that is potentially a lot of money wasted.
Let’s take a look at this example: you have a database that holds incoming user requests’ data, and you have a service that writes these requests onto the database. Imagine that the database was to become corrupt today at 1:00 pm:
- If the database was backed up one hour ago, then restored data copy ends at 12:00 pm and you’ll lose all user requests generated there afterward. This could result in repeated actions carried out by client managers or unanswered requests. Both can lead to money and reputational losses.
- If the last backup was made only a minute ago, then you will only lose the data generated within that last minute – isn’t this better?
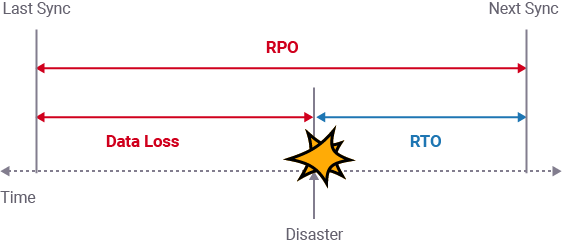
Obviously, any company that implements backup and disaster recovery strategies tend to minimize their RPO to the smallest value possible. But it is important to understand that lower RPOs can require a more expensive backup solution.
The overall outcome of setting a low RPO depends on data volume and current solutions, and the capabilities of its entire IT infrastructure. So, it is crucial to measure the actual volume of potential data loss that a company can afford. With this Recovery Point Objective in mind, you can make a measured decision on necessary backup or disaster recovery solutions.
- Direct-to-cloud recovery
- Recovery with bootable drive
- File-level and VM restore
- Remote recovery


Recovery Point Objective Сompliance
The RPO value can only be measured by businesses, as it is all about potential financial loss. By being an IT manager, you need to help business owners choose a balance between “how much data loss we can afford” and “how much money we have to spend on a backup project” to ensure business continuity.

Since you already have a backup infrastructure, you need to evaluate its capabilities of covering new business needs and/or replacing it with another solution, in case the previous one cannot scale more. Actually, the less expensive the solution, the more expensive it will be to recover in cases of emergency. Faster recovery, in most cases, requires the implementation of more complex and expensive hardware/software.
Clustered solutions with a shared database, for example, are built to recover almost instantaneously. But if the shared storage were to corrupt, you would need to recover data from a backup made some time ago. You can also use storage replication for shared cluster data, but RPO will definitely depend on the replication mechanism lag. The main rule here is the implementation of a “Plan B,” so you can meet agreed RPO values, in any case.
When the new backup and disaster recovery solutions have been deployed, it is important to do regular tests which can guarantee your compliance with agreed RPO/RTO. Remember that a carefully chosen RPO stands to prevent monetary loss, so you need to ensure that your system can meet the objective in case of data growth on infrastructure changes.
Summary
Meticulously planned backup and disaster recovery strategies are necessary for any solid business. The more time you spend on thorough planning, the less money your company will lose in case of disaster. Every Recovery Point Objective and Recovery Time Objective should be discussed with the business managers, as it has a direct influence on revenue and reputational risks. Once you have carefully planned and deployed proper data protection solutions, ensure it meets agreed values by performing tests with conditions close to reality.
Using MSP360 Backup, you can quickly deploy backup and recovery or disaster recovery solutions using cloud systems as storage backend or off-site data centers.
![]()
Read this free whitepaper to learn more about:
- Main components of business continuity
- Difference between business continuity and related concept
- Measurable metrics
