Backup and DR
Backup Types Comparison
Are you confused about the different ways to back up your data? Full, differential, incremental, synthetic full - it’s easy to get lost in the terminology. In this article, we cover shortly all backup types without being too specific. If you already know about all backup types and simply want to pick the needed one for your use -case - scroll down, there is a chart that will help you choose from different types of backup.
Full Backup
A full backup is a copy of the entire chosen dataset. Once you run a full backup, the selected data will be sent to the backup storage. This is the basic type of backup, and it is performed at the start of every backup job for obvious reasons.
Running only full backups each time is inefficient. Most likely most of the data has been already uploaded the previous time you ran the job. Of course, there are ways to upload only new and modified data. You can choose incremental, differential, or synthetic full backup types. Continue reading for more details on each.
Full Backup Fact Sheet
- The first backup is always a full backup. You might be running a differential, incremental, or a synthetic backup later, but you still need the first backup to be a full one.
- Full backup usually takes more storage space and time to complete than other backup types. That increases network and bandwidth load in the event of an offsite backup. We advise to run a full backup once in a certain period of time to ensure your backup set is consistent and leverage incremental or differential backup types for more frequent uploads.
- A full backup is more reliable than other backup types since it’s just a straight copy of the backup dataset.

Incremental Backup
Incremental backup is a type of backup that uploads only the data that was created after the previous backup.
In other words, you only back up new and updated files to the backup storage. An incremental backup is the most popular type of backup nowadays.

Further reading Incremental Backup
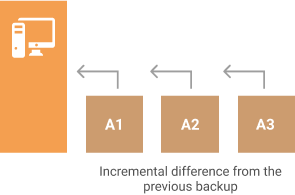
Incremental Block-Level Backup
Let’s imagine that you have files that are being constantly changed. In the classic incremental backup, you will end up backing up these files over and over again. However, there is a way to identify and upload only the changed parts of a file. This type of incremental backup is usually called an incremental block-level backup.
Incremental Backup Fact Sheet
- Incremental backup with block-level enabled is the most efficient of all types of backup in terms of resource consumption.
- Incremental backup without block-level backup is not effective on large and constantly changing files. It will re-backup entire files each time and cause the same inconveniences as a full backup.
- Data recovery from an incremental block-level backup is relatively slow. The backup software has to check each block in the sequence including the first full backup. After that, the software will assemble the file and download it.
- If any of the incremental block-level changes are lost, you will lose the entire backup. This is due to the architecture of the backup - each next backup is based on the changes made during the previous one. Thus, it is recommended to run a full backup from time to time to start a new backup chain.
A Side Note - Deduplication
Data consists of bytes: basic blocks, molecules, bricks, you name it. Some similar files have the same bytes. So, you may be wondering, if there is a way to backup only the chosen parts of files via the block-level backup, why not use the same technique but enable it for all similar files on the machine? Won’t it be more efficient and is that possible?
In fact, it is possible and this process is called deduplication. That is an advanced data storage technique typically used in an enterprise space. Check out more about deduplication in our article.
Differential Backup
Differential backup uploads all changed files since the first full backup was done. Differential backup might not seem very effective in the long run. It gets larger after each backup and eventually, it will outgrow the entire dataset. That means you need to perform a full backup from time to time. On the other hand, a differential backup is more reliable and faster than an incremental backup when it comes to recovery.
Further reading Differential Backup
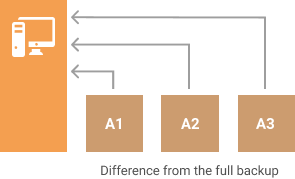
It might seem that an incremental backup is always a more preferable way of transfer, however, in some specific types of data that is not so. For example, a differential backup is used extensively in Microsoft SQL Server backups. Check out our article to learn more about the use cases of the differential backup.

Synthetic Full Backup
The synthetic full backup is an advanced way to perform subsequent full backups.
Previously in this article, we’ve mentioned that running a full backup from time to time is advised for all backup types. This will increase the durability of your data and create a thought-out and flexible retention policy.
Synthetic full backup works as follows:
- Checks if any parts of files on the storage correlate to those you are about to upload
- Copies that existing data inside the storage
- Adds only the new block of data from the machine to storage
Further reading Synthetic Full Backup Explained
Synthetic Full Backup Fact Sheet
- Synthetic full backup reaches the maximum efficiency with large files
- Synthetic full backup typically works much faster than a full backup
- When dealing with small changes on the machine, incremental block-level backups are still faster compared to a synthetic full backup.
Which Backup Types Are Right for Me?
As you already know, backup types cannot be directly compared to each other. To help you choose the best different types of backup, we’ve prepared this chart
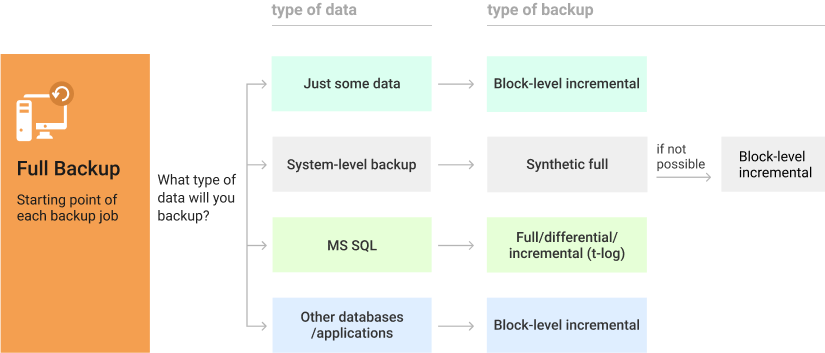
In a Nutshell
- You will always start with a full backup every time.
- Use an incremental backup for your files.
- Don’t forget to perform another full backup from time to time.
- If you run image-based backups, use the synthetic full option.
- When performing Microsoft SQL Server backup - stay with all three backup types: full, differential, t-log backup (it works like an incremental backup for SQL Server).
Once you've decided on the type of backup you need, try MSP360 Managed Backup, an advanced data protection solution designed to meet your business backup needs and supporting all types of backups listed in this guide.
Simple. Reliable.

