




Imagine the situation: you browse your Amazon S3 bucket and suddenly discover that some files are missing. Since Amazon S3 offers high durability, it leaves almost no chance for these files to disappear due to a system failure or disaster. Apparently, they were deleted by a user. How to find out who did that?
Table of Contents
Amazon S3 bucket logging can help you investigate the issue. This article will guide you through the S3 access logging configuration process.
Important: Bucket Logging should be enabled before the issue occurred to work as described.


How to Enable Amazon S3 Access Logs
Amazon S3 bucket logging provides detailed information on object requests and requesters even if they use your root account. First, let’s enable S3 server access logging:
1On Amazon S3 Console choose the bucket to enable logging
2Left click on the bucket
3Go to Properties and select Server Access Logging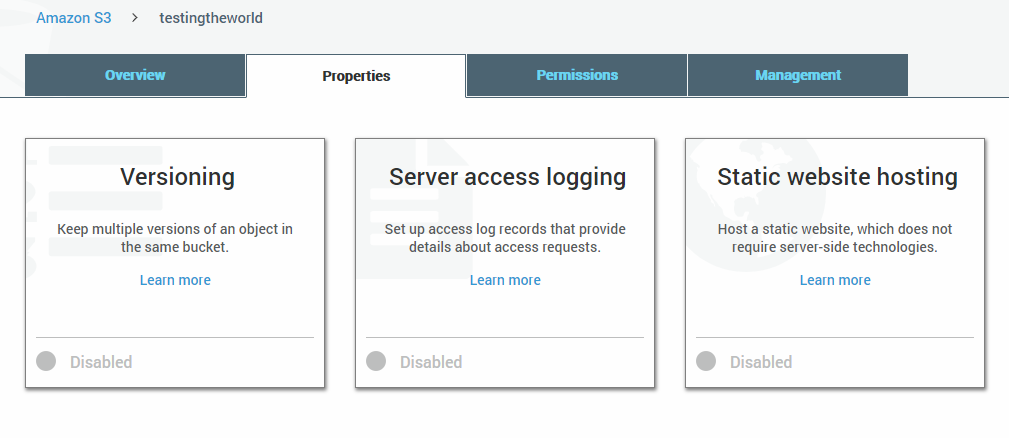
4Enable logging for the needed bucket. Choose a prefix to distinguish your logs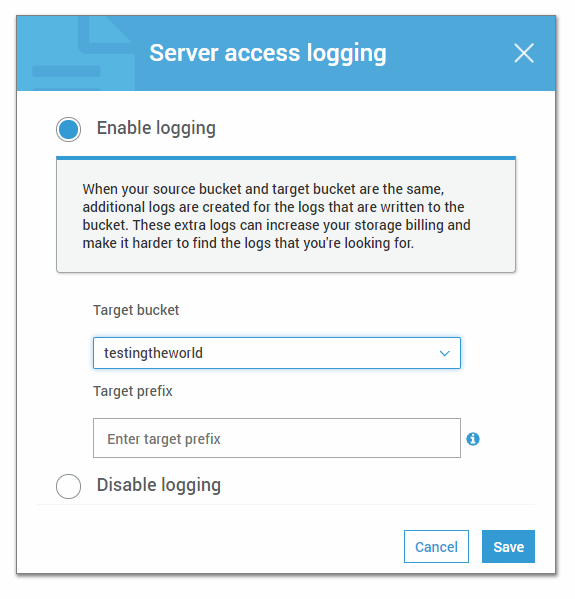
For the correct operation of the Amazon S3 bucket logging Target Bucket and the main bucket should be different, but situated in the same AWS region.
Now logging for Amazon S3 bucket is enabled and in 24 hours logs will be available for downloading.

How to Get Access to Amazon S3 Bucket Logs and Read Them
Amazon S3 Bucket Logs are simple .TXT files that can be downloaded and opened with any text editing software. The problem is when the user opens a log file in a Notepad, it looks like this:
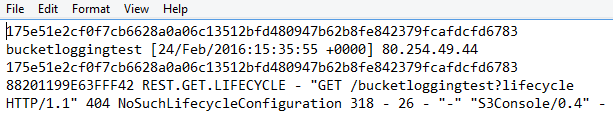
So, unless you’ve been reading log files for a couple of months, it’s relatively hard to understand who got access to the bucket and what operations were performed. Another problem is in the fact that AWS doesn’t collect all log entries in one document, but creates a new .TXT file for each operation. Therefore, the user will have to download and read each file separately to monitor security.
The solution is to use MSP360 Explorer for Amazon S3, which comes with a log viewer that facilitates reading.
1Right-click the bucket for which you enabled logging, choose Logging and then View Server Access Log: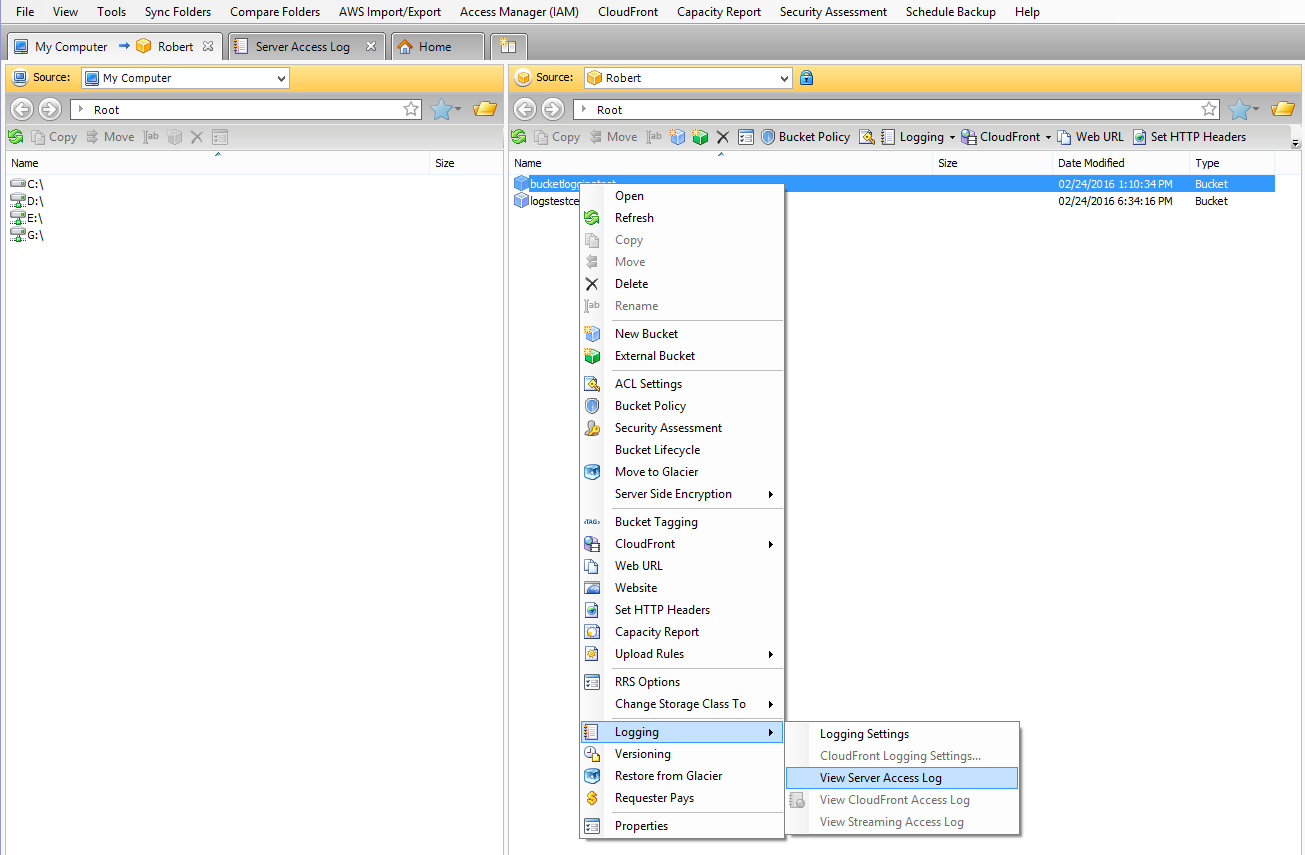
2You will see a new window pane with a complete bucket log for an exact period of time. 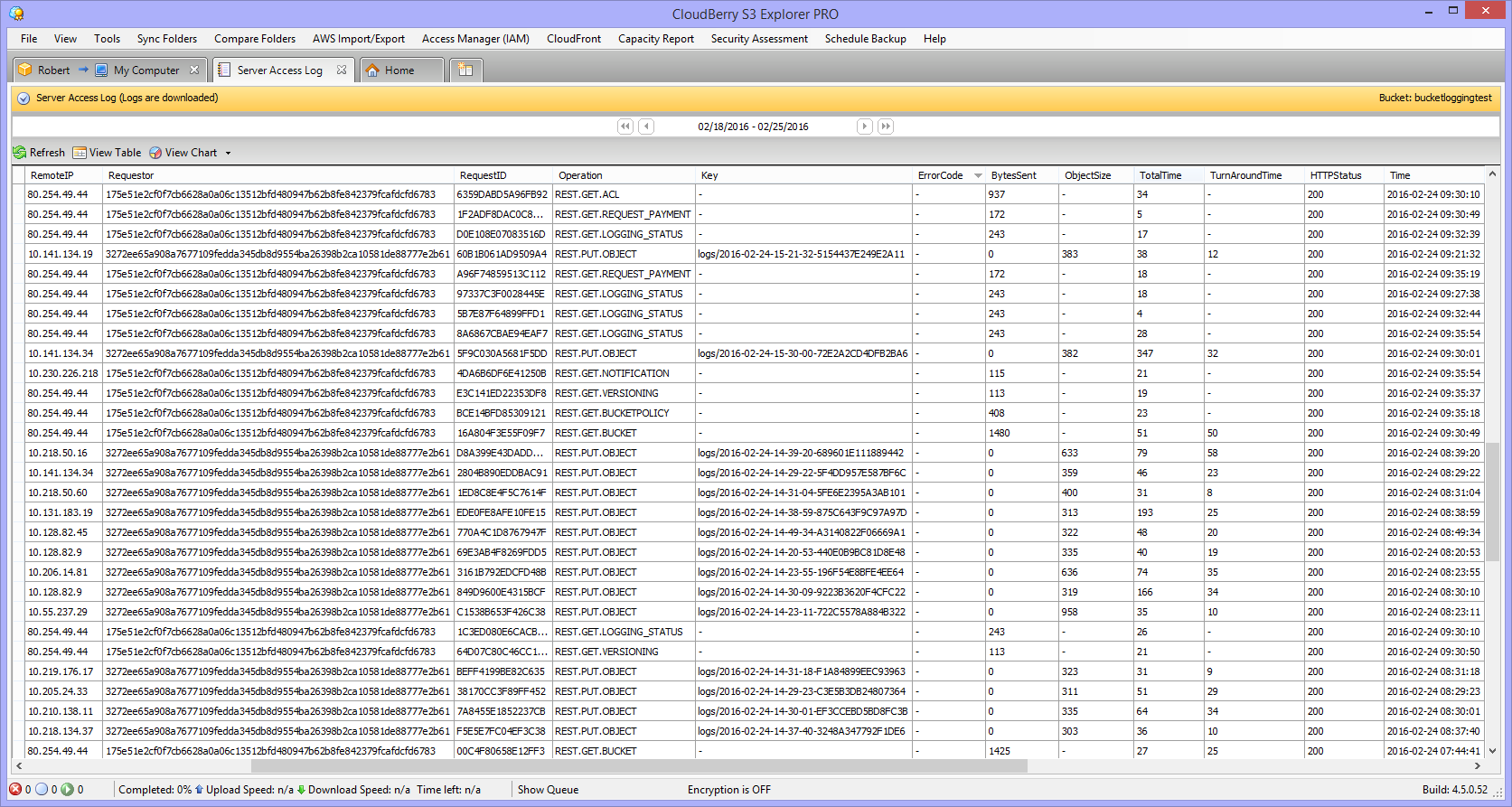
The last thing is to interpret the most important parameters that will help you understand who and when got access to the objects and edited them.
Remote IP — shows the IP address of the user who performed the operation. Remember that proxies and firewalls can hide the actual address.
Requester — this is the unique ID of the user who requested the file in your bucket. If the user wasn’t authorized the entry will show “Anonymous”, and if the user has an IAM role it will return the IAM user name and the root AWS account to which the IAM user belongs.
Operation — contains a list of operations performed with the file and the bucket.
Object Size — determines the total size of the object that was requested.
Now, you’ve enabled Amazon S3 server access logging for a certain bucket to improve account security and monitor operations performed by users during a certain period of time.
Remember that enabling of Amazon S3 access logs doesn’t protect your AWS account against fraud, so it is highly recommended to create IAM users instead of providing them with root account credentials.
- File management in Amazon S3 and S3-compatible storage
- Encryption and compression
- IAM and security management
