Backup and DR
Block-Level Backup Explained
In this blog post, we will give an overview of the block-level backup feature and show you how to use it to speed up your backup process, save storage space and machine resources.
What Is Block-Level Backup?
Block-level backup is a feature that allows uploading only the changed parts of files instead of whole files. In order to do that, it uses snapshot technology.
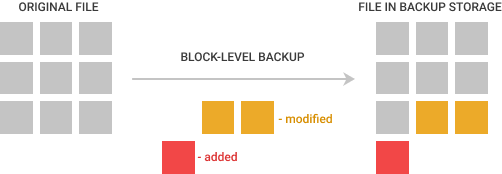
Block-level backup software reads data in the same sized blocks as the file system, or the parameter is chosen by software developers. Files ranging from 1 MB to 512 GB are split into 128 KB blocks; files ranging from 512 GB to 1024 GB are split into 256 KB blocks, and files ranging from 1024 GB to 1 TB are split into 512 KB blocks. For image-based, exchange and backup of virtual machines, the block is always 1 MB in size.
This is true for MSP360 Block-Level Backup.
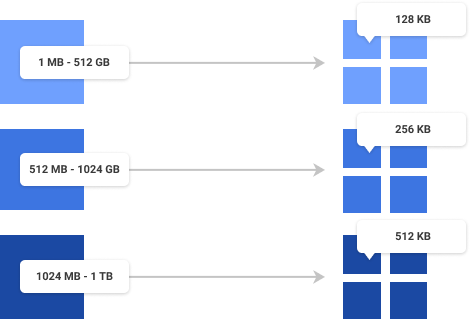
Files smaller than 1 MB are skipped by block-level backup.
New blocks are differentiated from the old ones via hashes. Block-level backup software calculates these hashes separately for each block and then compares them to their previous value. If there’s a mismatch, the block is uploaded to the backup repository. Hashes, in turn, are backed up and stored in the local repository. Therefore, newly added files will demand more storage space and CPU resources for hash calculations.
Hash is a data-function represented by a 16-bit value. If something in the file is changed - hash is also changed.
Block-Level Backup vs. File-Level Backup
Let’s compare block-level backup to the file-level approach. Both have pros and cons. The file-level approach is simple and widely used, but has a few flaws in comparison with file-level backup:
- Backup software has to go through all files and check if any of the files have been changed since the previous backup. This may be the reason why your backup job takes a long time.
- Also, for a large file, even a small portion of the file has been changed, the whole file has to be backed up.


Benefits of Block-Level Backup
Here are the benefits of performing block-level backups:

Upload operations require less time. Since block-level backup has fewer changes to upload to the storage, it takes a lot less time to perform.

It takes less storage space compared to a file-level backup.
 Less impact on machine performance. Block-level backup is always done by taking the snapshot of the running volume. Data is read from that snapshot, which allows the load to be decreased on the disks with the data.
Less impact on machine performance. Block-level backup is always done by taking the snapshot of the running volume. Data is read from that snapshot, which allows the load to be decreased on the disks with the data.
As a result of the aforementioned benefits, you can run backups more frequently. Because you don’t need to worry about causing performance issues, you can run block-level backups as frequently as you want.

Disadvantages of Block-Level Backup
Although block-level backup has significant benefits, there are facts you should know before switching to that backup feature:
 It might take longer to recover your data. To recover a single file, backup software has to check all blocks of that file, the initial full backup, and then rebuild the file using that information
It might take longer to recover your data. To recover a single file, backup software has to check all blocks of that file, the initial full backup, and then rebuild the file using that information
 Less data reliability and consistency. To recover a file in the block-level backup you need all consequent blocks to remain in their places. If by any chance, blocks become inconsistent, you will lose the ability to recover.
Less data reliability and consistency. To recover a file in the block-level backup you need all consequent blocks to remain in their places. If by any chance, blocks become inconsistent, you will lose the ability to recover.
To address both flaws, we recommend you perform a full backup from time to time. That will start a new backup sequence, thus making backups quicker to perform and easier to recover.
Block-Level Backup in MSP360 Backup Software
In MSP360 Backup, we have developed our own mechanism for block-level backup. You can run incremental block-level backups for various datasets including:
- Files and folders
- Image-based backups
- Exchange and other applications
- Backup of Hyper-V/VMware virtual machines
Next, we will overview how you can set up the block-level backup in MSP360 Backup.
To enable the block-level backup feature in MSP360 Backup, follow these steps:
- Download and install MSP360 Backup and sign up with a storage account of your choice.
- Open Backup Wizard and select the Use block level backup checkbox on the Advanced Options step.
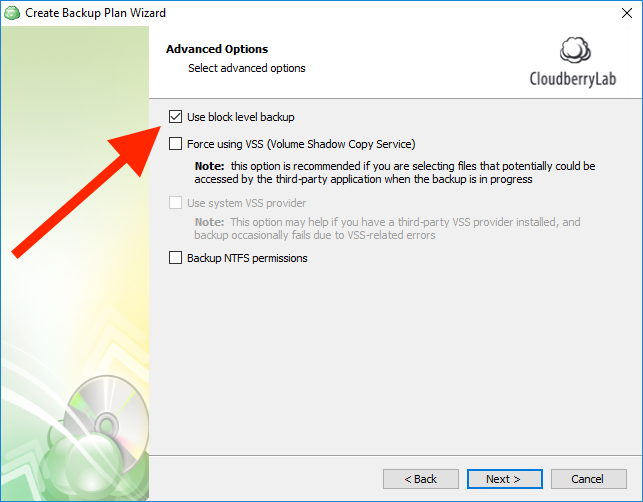
Select the Use block level backup checkbox on the Advanced Options step
3. On the first run of the backup, all files from the selected data set will be backed up. Next time you start a backup plan, only modified parts of the previously uploaded files will be moved to storage.
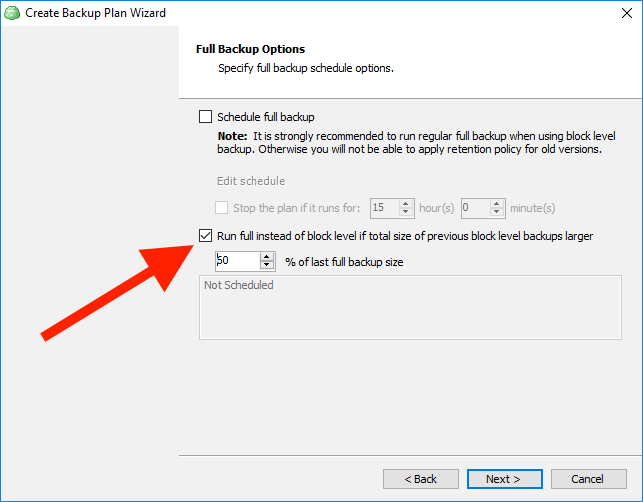
If you choose to use block-level backup, you will see the Full Backup Options screen where you can specify conditions of scheduling full backup. Full Backup is only related to block-level backup and is a part of it. Full Backup affects only individual files, not the whole backup set.
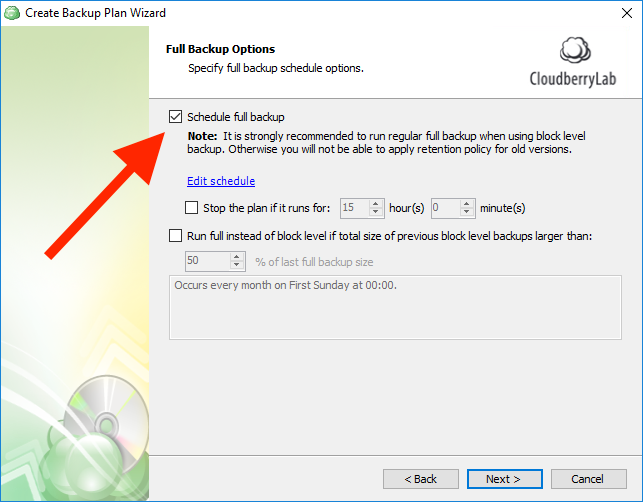
Enable initial full backup
Alternatively, you can enable block-level backup via the command-line interface if you prefer it to GUI:
Further reading MSP360 Backup Command Line Interface
Versioning
With MSP360 Backup you can set an expiration period for each version of the file and specify the number of versions to be kept on storage. See the settings on the screen below.
You can automatically remove all versions older than a certain time after the backup or modification date, set the number of versions, delay the purge, and even remove files that have been deleted locally from your storage after a certain time.
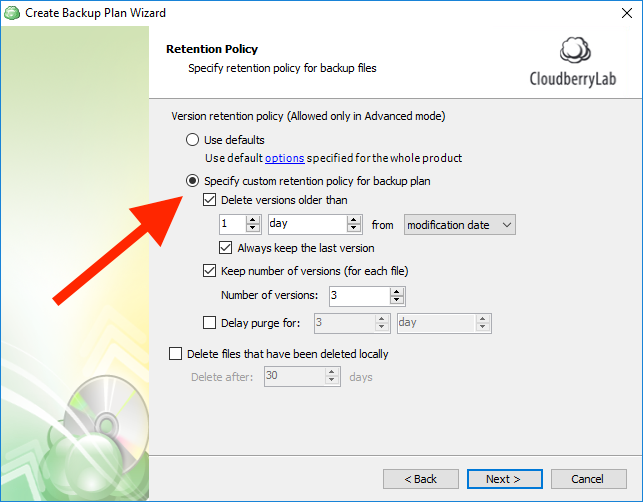
Set retention policy for your files
Here is an example of the block-level backup retention policy.
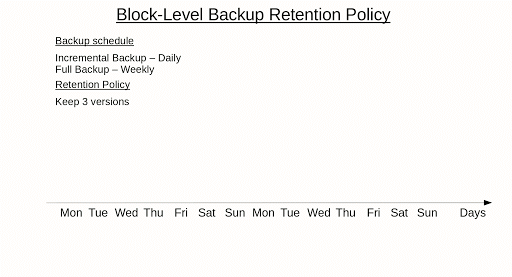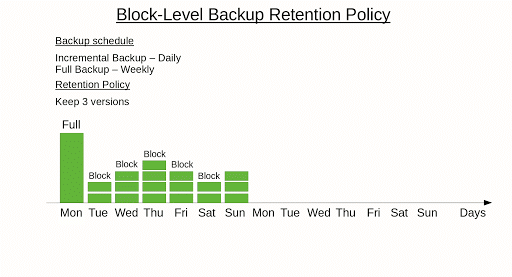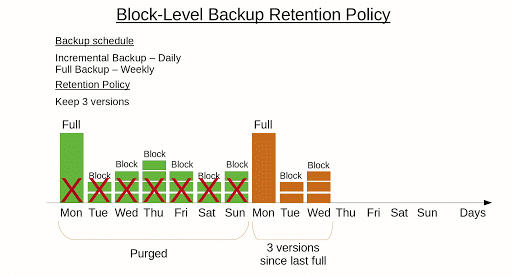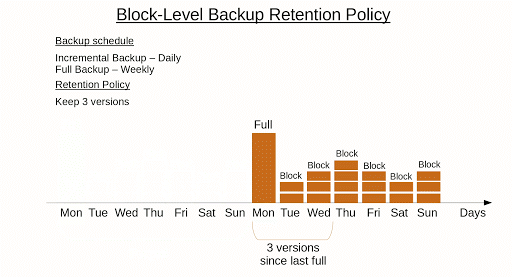
Further reading Backup Policy Best Practices
Specifying the Limit for Full Backup
As we mentioned before, it is strongly recommended to run full backups from time to time. On this backup step, you can specify the rule for automatic start of the new full backup.
Summary
Block-level backup is a great way to save your storage space, and save time and computing resources. However, in order to keep your data reliable, you should remember to perform full backups at times. Together these two backup types form an effective backup strategy.
Simple. Reliable.

