Backup and DR
Synthetic Full Backup Explained
What Is Synthetic Full Backup?
Synthetic full backup is a type of subsequent full backup that makes a comparison to the previously backed up data on the storage and uploads only the current changes from the backup source. Synthetic full backup helps to reduce the amount of data uploaded and accelerates a full backup creation. In this article, we will explain fully the concept of synthetic backup.

How Synthetic Full Backup Works
At the start of every new backup, you are running a full backup - uploading the given dataset to the backup storage. After this initial backup is completed you typically wait some time to perform the next one to keep up with all the changes that have occurred over time. That is called an incremental backup.
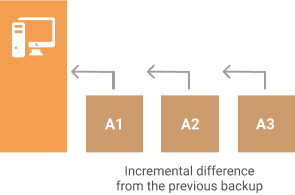
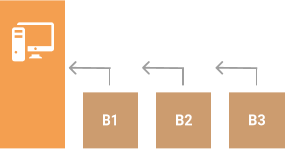
However, from time to time you need to perform another full backup. This might be needed in several cases:
- To be able to recover to several points in time
- If you fall under compliance and need to store several versions of files
- You are running an incremental block-level backup (it’s advised to run full backups from time to time in that case)
- You have an advanced retention policy for archiving purposes
A full backup takes a lot of time and resources. However, if the first full backup is essential any subsequent one is not.
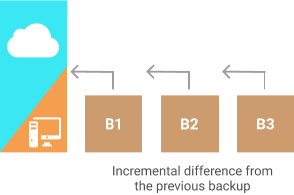
When you add a synthetic full backup to the backup sequence, the subsequent full backup the backup software checks the data on the storage and compares it to the data on the machine. Then the software uploads only the changes from the machine, the rest of the information is replicated inside the storage to create a new full dataset. This approach is especially effective when working with large files and datasets if there is limited bandwidth as it allows software to synthesize the most of the backup from data that is already on the storage. One good example is full system backup.


The Efficiency of Synthetic Full Backup
However, synthetic full backup has its limits and does not always works with the same efficiency. During the development of that feature, our team has performed numerous tests in various conditions. We also worked with a number of our clients who expressed interest in the beta-testing of that feature.
NOTE: We measure the efficiency of the synthetic full backup by checking how much data was uploaded from the machine to the amount of data synchronized on the storage.
Our tests have shown:
 Maximum efficiency of synthetic full backup will be achieved on the machine with a low fragmentation of its disks. The typical amount of data uploaded in the “medium user” scenario was 20% from the machine and 80% from the cloud. If the user does not change a lot on the given machine, we can achieve even higher rates of 10%/90%.
Maximum efficiency of synthetic full backup will be achieved on the machine with a low fragmentation of its disks. The typical amount of data uploaded in the “medium user” scenario was 20% from the machine and 80% from the cloud. If the user does not change a lot on the given machine, we can achieve even higher rates of 10%/90%.
 Medium efficiency of synthetic full backup was achieved on the machines of the “developers” - relatively high fragmentation with many frequent changes. Typical rates are 60%/40% and 40%/60%.
Medium efficiency of synthetic full backup was achieved on the machines of the “developers” - relatively high fragmentation with many frequent changes. Typical rates are 60%/40% and 40%/60%.
 The worst efficiency of synthetic full backup we experienced was when we changed nearly all the data on the machine between backups. We achieved 92%/8% of local data/cloud data changes.
The worst efficiency of synthetic full backup we experienced was when we changed nearly all the data on the machine between backups. We achieved 92%/8% of local data/cloud data changes.
Further reading: Backup Types Overview, Incremental Backup, Differential Backup-->
Simple. Reliable.

